



“DeepSeek-R1如同当年苏联抢发的第一颗卫星原神 足交,成为AI开启新时期的斯普特尼克时刻。”
2025年春节前,DeepSeek比除夕那天的烟花先一步辞世界上抽象开。
离除夕饭仅剩几个小时,国内某家云劳动器的工程师顿然被拉入职责群,接到要紧任务,要求其快速调优芯片,以适配最新的DeepSeek-R1模子。该工程师告诉咱们,“从接入到完成,通盘这个词进程不到一周”。
大岁首二,一家从事Agent To B业务的厂商负责东说念主电话被打爆,客户的要求肤浅随心:第一时分考据模子的确性能,尽快把部署提上日程。
节前大模子,节后只消DeepSeek。DeepSeek-R1就像一起分水岭,再行书写了中国大模子的叙事逻辑。

以2022年11月,OpenAI发布基于GPT-3.5的ChatGPT哄骗为发轫,国内自此走上了追逐OpenAI的说念路。2023年,大模子如星罗棋布般冒露面,无大模子不AI,各厂商你追我赶,百模大战初见头绪。
你方唱罢我登场,2024年的主东说念主公酿成了“AI六小虎”,AI创业成为新的故事剧本。仅一年的时分,智谱累计完成40亿元东说念主民币融资,月之暗面融资总和超13亿好意思元。在老本抛出橄榄枝后,他们站到了聚光灯下,一跃成为明星独角兽公司。
新的转化点发生在DeepSeek-R1爆火后,曾有一段时天职行业堕入了“一半火焰,一半海水”的境地,即一边积极拥抱学习R1,一边堕入了深深的内省。
犹豫是俄顷的,跟着百度、阿里、字节、腾讯、科大讯飞等厂商纷繁发布最新的推理模子,2025年的AI叙当事者题呼之欲出:“六大推理模子迎战OpenAI”。
推理模子确当打之年
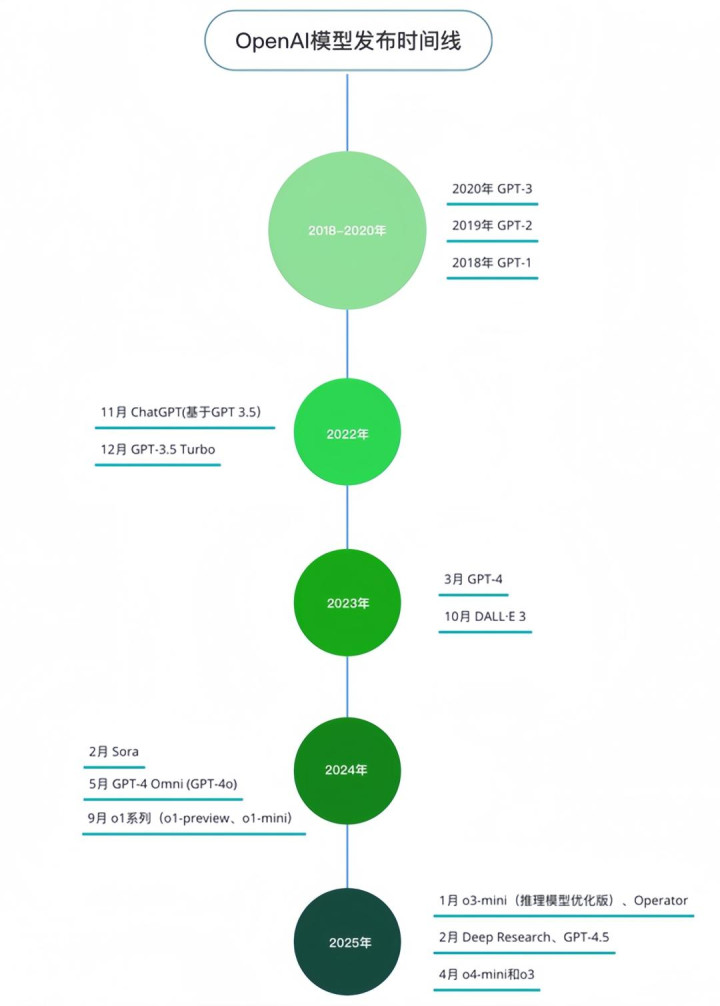
回看OpenAI的模子发布时分线,在基础模子标的,可以分为GPT系列和o系列,2024年OpenAI所发布的o1是一个里程碑式的转向。
(光子星球制图)
GPT系列是OpenAI最早构建的模子体系,聚焦当然言语处理、对话系统与文本生成,强调言语畅达性与高下文兼并能力。o系列是OpenAI于2023年新诞生的模子家眷,中枢聚焦“结构化推理”能力,强调模子的逻辑、分析、器用调用能力,是对GPT系列“言语偏重”路子的补充与彭胀。
未来GPT系列或将迟缓退出历史舞台。OpenAI在更新日记中秘书,自2025年4月30日起,GPT4将在ChatGPT中退役,将十足被GPT4o取代。
若是只是OpenAI自己工夫选拔,o系列和DeepSeek-R1并不会带来如斯宏大的影响。以底层模子架构例如,有公司选拔传统的Transformer架构,也有公司选拔自研架构。
o系列崛起有一个大布景,即大模子范式的篡改,从传统预试验阶段模子参数的Scaling Law,转化到强化学习推理计较带来新Scaling Law。这少许在OpenAI的o3诱导进程中得到了考据,OpenAI不雅察到大范畴强化学习进展出与GPT系列预试验中不雅察到的趋势疏浚,计较量越大,性能越好。
简而言之,即是让AI我方规画、学习、反馈和完成任务,这与如今大热的Agent所需具备的能力一致。
有工夫东说念主员告诉光子星球,o1以后所发布的“Deep Research”Agent,十足基于模子重新试验,且未公开念念维链推理进程。“这意味着底座模子能力径直决定了Agent的落地效果”原神 足交,想要在大模子第二程变得有竞争力,推理模子险些成为了必选。
站在公司和工夫一号位角度,第一时分跟进o1和DeepSeek-R1是一种判断和眼神,但同期也代表瞩目干预与高风险。
咱们了解到国内的许多公司,口头上有自研大模子,但实则是“套壳”。o系列站在GPT的肩膀上出生,这导致地基不牢的公司只可尖嘴猴腮。另一方面,融资和营业化变现的压力,又淘汰了一批公司。
(光子星球制图)
于是,咱们发现旧年星光灰暗的大厂们,成为了响应最快,跟进最实时的代表。
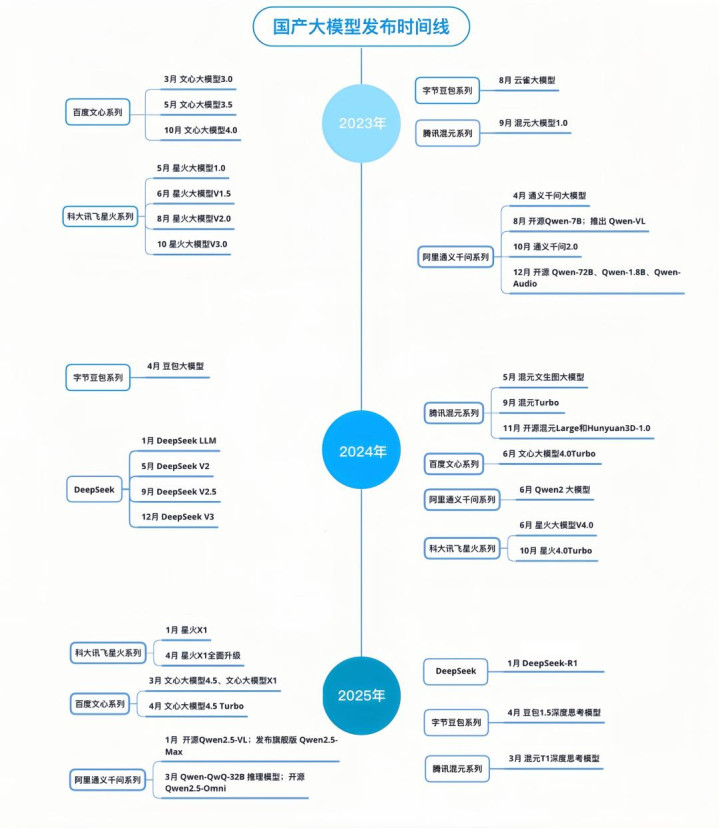
以DeepSeek-R1(2025年1月20日发布)为时分基准线,当月科大讯飞就发布了深度推理大模子——讯飞星火X1;3月,百度发布文心大模子X1,阿里发布通义千问Qwen-QwQ-32B推理模子,腾讯发布混元T1深度念念考模子;4月,字节豆包1.5深度念念考模子上线,同期讯飞星火X1迎来升级,发布“快念念考、慢念念考兼并模子”。
上述厂商有一些共同之处,跟上了每一次的模子能力升级进程,在转向推理方上前,其基础模子能力基本王人达到了GPT-4的水平。以此算作参照,这可能是迈入大模子第二阶段的基本条款。
六大推理模子混战o3
o3当今是OpenAI最宏大的推理模子。网好意思妙传的一张大模子IQ图表现,东说念主类平均IQ为100,o3才能达到了惊东说念主的136。
测试数据表现,o3在多项基准测试中卓绝了o1的性能,绝顶在分析图像、图表和图形等视觉任务中进展尤为出色。
在外部巨匠的评估中,o3在贫穷的执行任务中比o1犯的首要轻视减少20%,在编程、营业、盘考和创意构念念等领域王人有可以的进展。
需要承认的是,OpenAI存货照实有两把刷子,继o1之后,o3又成为了新的大模子性能攀缘岑岭。但国内各大模子厂商的跟进速率并不慢,若以DeepSeek-R1为参考模范,百度、阿里、科大讯飞、字节、腾讯后头所发布的推理模子水平收支不大,部分在一些测试目标上致使有卓绝。
放纵当今,国产六大推理模子各有千秋。
DeepSeek-R1的兴趣兴趣可想而知,好意思满的工夫走漏和开源部署,赐与了行业推理大模子试验念念路。掀开了OpenAI闭源的“黑匣子”,获胜复刻出了性能收支无几的o1。R1杰出的性情是“花小钱办大事”,高效且追求极致性价比。在十分有限的算力、数据等资源干预的情况下,试验成本却仅为560万好意思元,远低于好意思国AI公司的数千万好意思元乃至数亿好意思元干预。
一位知情东说念主士告诉咱们,DeepSeek-R1和一些国产推理大模子不组成径直竞争敌手。在B端业务中,当今阿里开源的千问系列模子占比更重。“全尺寸和全模子,就像一个全家桶,可以供客户选拔。32B的模子大小,跑起来成本也不是很高”。
百度在这波中从生态层面接入了DeepSeek,这给了用户更多选拔权,开源和免费的战略或将能诱骗更多用户。文心大模子X1接受“念念维链-行径链”协同试验,在复杂任务中自动拆解为二十多个推理体式,同期可以调用十几种的器用链,以此来增强Agent的能力。
有参与过与百度互助的东说念主士告诉光子星球,在金融、医疗、政务等一些垂类领域,百度会“穿针引线”,把一些相干业务的公司攒到一个局。“百度提供基础模子,咱们提供另一方所需的工夫,终末径直跟百度核算”。通过这种花样,百度正束缚减轻To B大模子商场与科大讯飞之间的差距。
科大讯飞的星火X1,是刻下业界惟一基于宇宙产算力试验的深度推理大模子。
恰是基于全栈国产、自主可控的上风,科大讯飞的星火大模子倍受央国企和政府客户的嗜好,保持行业端当先。4月21日,星火X1升级进步了通用能力,也同步增强了面向行业的处理决策能力。在重心行业,如老到、医疗、执法等领域的测试中,王人得回了越过OpenAI和DeepSeek的分数,这些能力无疑会在本年大模子订单中有所体现。
星火X1一个模子同期援助两种念念考模式,进步了模子处理不同复杂度任务的能力,满血版星火X1仅需4张卡(华为910B)即可部署。与华为的深度互助,以及束缚迭代的底座大模子能力和宏大的行业大模子落地体系,一经成为科大讯飞在一众大厂会剿中杰出重围的三大利器。
国内闭源大模子中,豆包模子被评价为“有一订价钱竞争力”。一位作念AI玩物的厂商告诉咱们,他的居品接入了多家大模子,在用户使用进程中,优先使用各家的免费Token额度,“一朝超事后,优先切换豆包,价钱能按捺在相比低的成本”。
旧年,豆包参与主导了价钱战,豆包大模子价钱降至0.0008元/千Tokens,豆包视觉兼并模子订价0.003元/千Tokens,均低于那时行业平均水平。此外,豆包大模子是工夫落地AI哄骗居品值得鉴戒的案例,端到端的实时语音工夫、多模态、Agent工夫王人能在第一时分介入豆包哄骗端,这亦然援助其快速迭代更新的原因之一。
腾讯混元入场较晚。有职工曾向咱们示意,混元团队成员大部分畴前是搜索保举告白出身,跟通义、字节能够有一定差距,“打鸭子上架,好像也没什么明确标的,东一下西一下”,“一群生手东说念主诱导内行东说念主”。加之东说念主员的荏苒,导致了混元曾一度处于停滞现象。
借着DeepSeek崛起的东风,元宝一经悄然落幕了逆袭。至少从数据层面看,一经取得阶段性效果。一位里面东说念主士告诉咱们,2025年春节以来的这几个月,腾讯倾注了通盘这个词集团资源对元宝进行实践,无论线下行径资源,照旧微信导流或者预算干预,关于元宝王人是重心歪斜,通过这种浪漫出遗迹的花样,逆转了此前十足被迫的时势。
从当今各公司的商场反馈来看,云霄多模调用一经迟缓被招供,各家模子并存,用户按需调取才是未来。在执行情况中,客户最终是否选定一款大模子,模子性能只是一项推测模范,背后可能还波及数据、生态等多方面的考量。
大模子将全面国产化?
自DeepSeek-R1运行,国产推理大模子成为了各榜单的常客,AI开源社区的用户以的确的下载量和Star数来援助中国AI的发展。
即便如斯,刻下大模子仍濒临着或多或少的“卡脖子”的问题。
近期,有音信称,英伟达已通过非精采渠说念示知其AIC互助伙伴(如七彩虹、影驰、同德等),暂停GeForce RTX 5090D的销售和出货。这一举措被以为是英伟达在应酬海外环境变化的谨防性措施。
尽管英伟达尚未发布精采公告,但业内宽阔以为,RTX 5090D的供应已进入“暂停现象”,这只是才只是运行。
若从源流上被法例,英伟达必将际遇愈加大宗的逝世,而好意思国以异邦度的大模子发展将际遇不信服性,追逐OpenAI的步履也将受到一定的阻碍。
在此布景下,宇宙产化工夫旅途将越来越成为全球的备选项。这其中,科大讯飞作念了较为充分的准备。据了解,科大讯飞与互助伙伴聚拢通过四大中枢工夫优化,落幕MoE模子集群推感性能翻倍进步。
说明最新测试集评测落幕,星火X1在通用任务效果评测中全面对标OpenAI o1和DeepSeek R1,在数学、学问问答等方面进展杰出,这标明在工夫自主可控的说念路上,中国AI已具备与海外顶尖模子同台竞技的实力。
ai换脸刘涛旧年气候无穷的AI六小虎,如今早已东奔西向,境遇迥然。被DeepSeek击碎“AGI瞎想”“学术天才创业”和“明星AI居品”的月之暗面,追想到低调的工夫研发中;将底层工夫和居品解绑后的MiniMax,加大了对工夫的干预,标的相同为Agent和推理模子;六小虎中的智谱终于盼来了行将IPO的好音信,不外其全体营收、估值以及能否获胜落幕IPO,仍充满变数。
旧年,Kimi、海螺AI等AI哄骗的出圈,俄顷地迎来了AI公司的高光时刻。但本年,推理模子一经成为了国内各大厂商角逐的枢纽标的,AI六小虎的标的与大厂高度重合,而决定他们能否生活下去的“口粮”则执在大厂们的手上。
如今,跟着六大推理大模子的全面崛起,以及海外环境的不信服性加重,全栈国产化大模子有望将成为一种新的主流。
从半导体、工业软件与信创再到今天的AI芯片原神 足交,历史的劝诫告诉咱们,想要开脱被制约的近况就得落幕自给自足,将运道紧紧掌执在我方手中。能够在不久的将来,越来越多的国产大模子将走上全栈国产化抗争OpenAI们的说念路。